While there are numerous advantages of deploying on the cloud, there are no guarantees that the cloud platform services will respond successfully every time. In a cloud environment periodic transient failures should be expected. The approach should be to minimize the impact of such failures on the application execution by anticipating and proactively handling failures.
The Problem with Cloud Services
The cloud is made up of hardware components that work together to present a service to the user. Since hardware is subject to failure, cloud services cannot guarantee 100% uptime. Small failures could cascade and affect multiple services, all of some of which could be down for brief periods of time.
When the consumer’s use of the cloud service exceeds a maximum allowed throughput, the system could throttle the consumer’s access to the particular service. Services deploy throttling as a self-defense response to limit the usage, sometimes delaying responses, other times rejecting all or some of an application’s requests. The onus is on the application to retry any requests rejected by the service.
What Needs to be Done?
Cloud applications need to retry operations when failures occur. It does not make sense to retry the operation immediately because most failures should be expected to last for a few minutes at least. We will consider a scenario where the database service is unavailable for a short time.
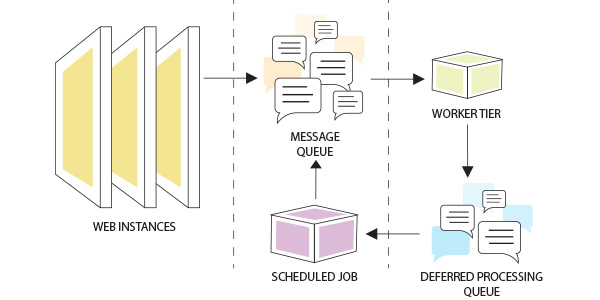
The figure above shows the flow of the operation which encounters a transient failure and the possible approach to recover from it. The message sent by the web instance is added to the primary message queue. This message is picked up for processing by the worker instances.
When the worker tries to write data to the database tier, it encounters a failure. In this case, the worker adds the data to be written to a “Deferred Processing Queue”.
A scheduled job runs every 5 minutes, listens to the “Deferred Processing Queue” and consumes the messages from this queue for processing. The scheduled job reinserts the message into the primary message queue where it is read by the worker instances and processed successfully if the database service is available. If not, the same process is followed again. This allows the cloud application to process the messages at a deferred time, and makes it resilient to failures.
Summary
Transient failures are a common phenomenon in cloud applications. A cloud-based application is expected to withstand such transient failures and prevent loss of data even under extreme circumstances.