In previous posts, we covered the benefits of moving to the cloud for scale and the design principles of building scalable applications. In this post, we will look at a typical reference architecture for a cloud based scalable application and cloud features that help your application scale.
Architecture
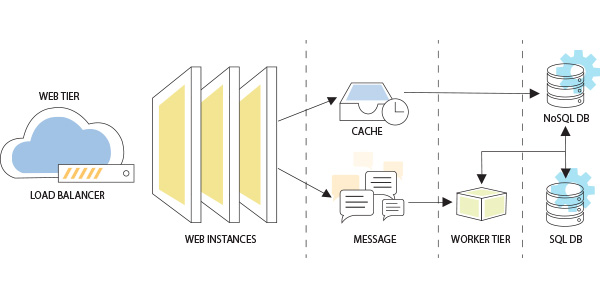
The below listed figure illustrates a reference architecture commonly used by scalable applications. The architecture has the following usual suspects that allow it to handle high traffic and load patterns experienced by typical scalable applications:
- Load Balancer(s) for the web tier.
- Auto-scaling for web and worker instances.
- Message queue
- Cache
- SQL and/or NoSQL database(s).
Load Balancer
Load balancers are used to distribute load on application services across multiple systems. This allows the application to scale horizontally, and allows the application to add more capacity transparently in response to demand. By fronting application services using a simple proxy, a load-balancer provides clients a single internet location to communicate with, while fanning out backend processing across multiple service instances. A load balancer can be used for any service within the application as needed. Most commonly a load balancer is used to front web instances.
Load balancers typically use a round-robin algorithm to route traffic to the service layer. In advanced configurations, they can also be configured to control the volume of traffic routed to different instances.
Sticky Sessions
For legacy applications, load balancers also support session stickiness, which means the load balancer routes all requests for a given session to a single instance. This can be used in case the concerned tier is not stateless. Since implementations of load balancers vary, consult the respective documentation to understand how sticky sessions are handled.
Most cloud vendors have load-balancing available as-a-service. On Amazon Web Services, you can configure a load-balancer to front a set of EC2 instances that checks for health of the instances periodically and routes traffic to them only if they are healthy.
Web Tier
A stateless web tier makes it easy to support horizontal scaling. As discussed in part 2, REST web services are designed to be stateless and therefore conducive to scale horizontally. Some modern frameworks that allow rapid creation of web apps are Dropwizard, Spring Boot (java), node.js and express (javascript).
Auto Scaling
Since the web tier is consumer facing, it is normally set up to auto-scale. Most cloud vendors support autoscaling by monitoring certain characteristics of the instances to be scaled. On Amazon Web Services, it is possible to track CPU usage or network bandwidth usage of instances and respond to extreme events by scaling out (expanding) or scaling in (contracting). To avoid cost escalation, you can also specify a higher limit for the number of instances auto-scaling will spawn.
Cache
Caching drives down access times for most frequently used documents. Since documents are stored in-memory the response times for web apps can improve manifold by using a cache. For e.g. User information might hardly change during the course of a session, but related information such as user permissions and role information needs to be accessed frequently. Therefore, the user information and the related roles and permissions are prime targets to be cached. This will result is faster rendering of pages that need to assess permissions before displaying data.
Redis and Memcached are two of the most popular caches available. Amazon web services provides both the implementations in the Elasticache offering.
CDN
Content-Delivery-Networks or CDNs are used to deliver static artifacts such as pictures, icons and static HTML pages much faster than a regular “single-source” website. Cloud vendors provide access to CDNs that will replicate static resources closer to the customer, thereby reducing latency. This results in excellent load times especially if there are large images and/or videos being used on the site or application.
Amazon Web Services CloudFront automatically identifies and serves static content from the closest datacenter irrespective of the region the site is hosted in. This results in drastic reduction of latency and faster loading of web artifacts.
Message Queue
Asynchronous communication ensures that the services/tiers are independent of each other. This characteristic allows the system to scale much farther than if all components are closely coupled together. Not all calls in your system need to be asynchronous. You can use the following criteria to qualify a call as asynchronous communication.
- A call to a third party or external API.
- Long running processes.
- Error prone/changed frequently methods.
- Any operation that does not need an immediate action as a response.
While you implement the message bus based asynchronous communication, you need to take care that the message bus can scale to the rise in traffic. RabbitMQ is a popular message-oriented middleware used by many applications. You can also consider ActiveMQ, Kafka and Amazon SQS as the other message queue options.
Worker Tier
Similar to the Web tier the worker tier too needs to support horizontal scaling. The worker instances are independent processes that listen to the message queue and process the message as they are received.
The message bus size is a good parameter to monitor for scaling such that the number of worker instances increases with the increase in the number of message in the queue. Amazon AWS Auto Scaling groups and Rackspace Auto Scale are some examples of auto scaling options available with the respective cloud platforms.
Database Tier
A typical Database Tier of a scalable application would make use of both NoSQL and SQL databases as each of these have their own advantages. NoSQL can be used in the following scenarios where:
- A relational database will not scale to your application’s traffic at an acceptable cost.
- The data is unstructured/”schemaless”. The data does not need explicit definition of schema up front and can just include new fields without any formality.
- Your application data is expected to become so massive that it needs to be massively distributed.
- The application needs fast key-value access.
You should avoid the use of NoSQL and use RDBMS databases in scenarios where:
- Complex/dynamic queries are needed. Complex queries are best served from an RDBMS.
- Transactions need guarantee of ACID (Atomicity, Consistency, Isolation, Durability) properties.
When it comes to NoSQL databases there are multiple options available like MongoDB, Cassandra, AWS DynamoDB and CouchDB. Google recently announced the availability of, Google Cloud Bigtable, a NoSQL database that drives nearly all of Google’s largest applications including Google Search, Gmail and Analytics.
Summary
We discussed the various components of a reference architecture that can be used to run different types of applications on the cloud. Each application will dictate the nature and scale of usage of these different components, but most applications will need all of these components to achieve scale. Most cloud vendors have managed service offerings that provide access to these components.